머신러닝의 지도학습에 속하는
Classfication(분류)
- Logistic Regression (로지스틱 회귀)
- KNN(K nearest neighbor) 알고리즘,
- SVC(Support Vector Machine) 알고리즘,
- DT(Decision Tree) 알고리즘
네 가지 방법 중에 정확도가 더 높은 방법으로 알고리즘을 선택하여 사용한다
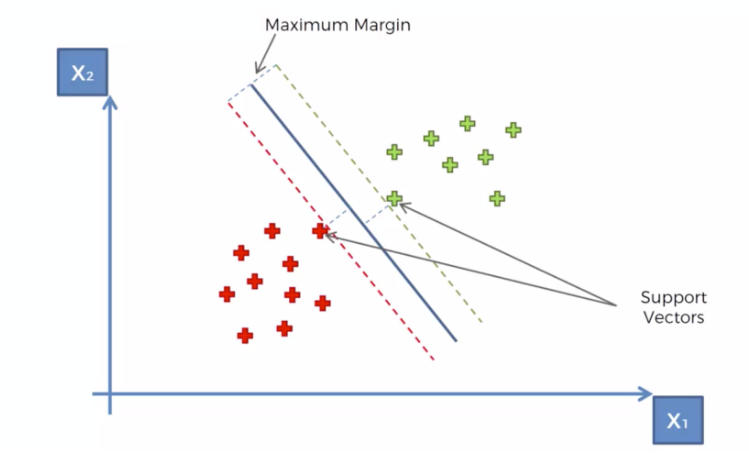
SVM(Support Vector Machine)
- SVC (Support Vector Classifier):
- SVC는 분류 문제를 해결하기 위한 SVM의 변형이다
- 이것은 주어진 데이터를 분류하기 위해 최적의 분리 초평면을 찾는다
- SVC는 클래스 간의 경계를 분리하기 위해 최적의 초평면을 찾는 것이 목표
- SVR (Support Vector Regressor):
- SVR은 회귀 문제를 해결하기 위한 SVM의 변형이다
- 이것은 주어진 데이터를 사용하여 연속적인 값(숫자)을 예측하는 데 사용된다.
- SVR은 주어진 데이터의 패턴을 학습하고, 예측하려는 값에 대한 최적의 예측 초평면을 찾는다.
SVC와 SVR 모두 SVM의 기본 아이디어를 따르지만, 분류와 회귀 문제에 대해 각각 다른 목표를 가지고 있다. 분류 문제에서는 클래스 간의 경계를 분리하는 초평면을 찾는 반면, 회귀 문제에서는 데이터의 패턴을 학습하고 예측값에 가까운 초평면을 찾는다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df
| User ID | Gender | Age | EstimatedSalary | Purchased | |
| 0 | 15624510 | Male | 19 | 19000 | 0 |
| 1 | 15810944 | Male | 35 | 20000 | 0 |
| 2 | 15668575 | Female | 26 | 43000 | 0 |
| 3 | 15603246 | Female | 27 | 57000 | 0 |
| 4 | 15804002 | Male | 19 | 76000 | 0 |
| ... | ... | ... | ... | ... | ... |
| 395 | 15691863 | Female | 46 | 41000 | 1 |
| 396 | 15706071 | Male | 51 | 23000 | 1 |
| 397 | 15654296 | Female | 50 | 20000 | 1 |
| 398 | 15755018 | Male | 36 | 33000 | 0 |
| 399 | 15594041 | Female | 49 | 36000 | 1 |
구매 한다 : 1
구매 안한다 : 0
어느쪽에 가까울지 카테고리하기
특성열과 대상열로 나누기
특성 열(X)은 데이터셋에서 각각의 관측치에 대한 설명변수를 나타낸다
대상 열(y)은 예측하려는 값이 포함된 열이다
y = df['Purchased']
X = df.loc[ : , 'Age' : 'EstimatedSalary']
피처스케일링
from sklearn.preprocessing import StandardScaler
X_scaler = StandardScaler()
X = X_scaler.fit_transform(X)
train과 test로 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
모델링하기
from sklearn.svm import SVC
classifier = SVC()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
confusion_matrix
from sklearn.metrics import confusion_matrix, accuracy_score
confusion_matrix(y_test, y_pred)
array([[49, 9],
[ 3, 39]], dtype=int64)
정확도 구하기
accuracy_score(y_test, y_pred)
0.88
'ML (MachineLearning)' 카테고리의 다른 글
| K-Means 알고리즘 (0) | 2024.04.16 |
|---|---|
| DTree(Decision Tree) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |
| KNN(K nearest neighbor) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |
| 데이터 불균형이 발생할 때, 데이터 리샘플링하기 (0) | 2024.04.15 |
| Logistic Regression (로지스틱 회귀) (0) | 2024.04.15 |