Prediction
- regressor (회귀모델)
머신러닝 regressor는 지도(학습)모델로 과거 데이터를 입력시켜주면 그에 대한 예측값을 알려주는 모델이다.
회귀 모델은 주로 예측하려는 값이 연속형 데이터인 경우에 사용되며 특정한 데이터에 대한 패턴을 학습하고, 그 패턴을 기반으로 새로운 입력에 대한 값을 예측한다
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
문제 ) 머신러닝을 통해 Purchased 값을 알고싶다.
df
| Country | Age | Salary | Purchased | |
| 0 | France | 44.000000 | 72000.000000 | No |
| 1 | Spain | 27.000000 | 48000.000000 | Yes |
| 2 | Germany | 30.000000 | 54000.000000 | No |
| 3 | Spain | 38.000000 | 61000.000000 | No |
| 4 | Germany | 40.000000 | Nan | Yes |
| 5 | France | 35.000000 | 58000.000000 | Yes |
| 6 | Spain | Nan | 52000.000000 | No |
| 7 | France | 48.000000 | 79000.000000 | Yes |
| 8 | Germany | 50.000000 | 83000.000000 | No |
| 9 | France | 37.000000 | 67000.000000 | Yes |
먼저 nan처리를 해준다
1) 삭제전략 dropna
2) 채우는전략 fillna
중, 1번 삭제전략을 통해 nan을 처리하면 아래와 같다
df.dropna()
df
| Country | Age | Salary | Purchased | |
| 0 | France | 44.000000 | 72000.000000 | No |
| 1 | Spain | 27.000000 | 48000.000000 | Yes |
| 2 | Germany | 30.000000 | 54000.000000 | No |
| 3 | Spain | 38.000000 | 61000.000000 | No |
| 5 | France | 35.000000 | 58000.000000 | Yes |
| 7 | France | 48.000000 | 79000.000000 | Yes |
| 8 | Germany | 50.000000 | 83000.000000 | No |
| 9 | France | 37.000000 | 67000.000000 | Yes |
학습데이터 X와 결과데이터 y로 분리
먼저, 머신러닝을 학습시킬 데이터 X와 결과를 도출시키는 테스트 데이터 y로 분리한다
y
| Purchased | |
| 0 | No |
| 1 | Yes |
| 2 | No |
| 3 | No |
| 5 | Yes |
| 7 | Yes |
| 8 | No |
| 9 | Yes |
X
| Country | Age | Salary | |
| 0 | France | 44.000000 | 72000.000000 |
| 1 | Spain | 27.000000 | 48000.000000 |
| 2 | Germany | 30.000000 | 54000.000000 |
| 3 | Spain | 38.000000 | 61000.000000 |
| 5 | France | 35.000000 | 58000.000000 |
| 7 | France | 48.000000 | 79000.000000 |
| 8 | Germany | 50.000000 | 83000.000000 |
| 9 | France | 37.000000 | 67000.000000 |
문자열을 숫자로 바꿔주기
-컴퓨터가 이해할 수 있도록 문자로 된 데이터는 숫자로 변경해주어야 하는데, 이를 원 핫 인코딩이라고 한다.
원핫 인코딩의 예상 결과를 작성해보았다
# France Germany Spain Age Salary
# 1 0 0 44 72000
# 0 0 1 27 48000
# 0 1 0 30 54000
# 0 0 1 38 61000
# 1 0 0 35 58000
# 1 0 0 48 79000
# 0 1 0 50 83000
# 1 0 0 37 67000
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
<원핫 인코딩 공식>
ColumnTransformer( [ ('encoder', OneHotEncoder() , [] ) ] , remainder= 'passthrough' )[]안에 있는 인덱스 번호는 원핫인코딩하고, remainder 나머지는 passthrough 변형시키지말고 지나쳐라
ct = ColumnTransformer( [ ('encoder', OneHotEncoder() , [0] ) ] , remainder= 'passthrough' )
X = ct.fit_transform(X)
array([[1.0e+00, 0.0e+00, 0.0e+00, 4.4e+01, 7.2e+04],
[0.0e+00, 0.0e+00, 1.0e+00, 2.7e+01, 4.8e+04],
[0.0e+00, 1.0e+00, 0.0e+00, 3.0e+01, 5.4e+04],
[0.0e+00, 0.0e+00, 1.0e+00, 3.8e+01, 6.1e+04],
[1.0e+00, 0.0e+00, 0.0e+00, 3.5e+01, 5.8e+04],
[1.0e+00, 0.0e+00, 0.0e+00, 4.8e+01, 7.9e+04],
[0.0e+00, 1.0e+00, 0.0e+00, 5.0e+01, 8.3e+04],
[1.0e+00, 0.0e+00, 0.0e+00, 3.7e+01, 6.7e+04]])
설명 ) 4.4e+01은 4.4*10=44 , 7.2e+04는 7.2 * 10000 = 72000을 표현한 것이다.
y는 No, Yes로 0과 1 두개로 표현할 수 있으므로 그냥 인코딩한다
| Purchased | |
| 0 | No |
| 1 | Yes |
| 2 | No |
| 3 | No |
| 4 | Yes |
| 5 | Yes |
| 6 | No |
| 7 | Yes |
| 8 | No |
| 9 | Yes |
sorted(y.unique())
y = encoder.fit_transform(y)
array([0, 1, 0, 0, 1, 1, 0, 1])
Feature Scaling
딥러닝 등과 같은 경우에는 feature scaling을 통해 데이터의 스케일을 조정하여 모델의 안정성을 향상시키고 성능을 향상시켜야 한다.
방법은 두가지이다. (두가지 중 하나를 선택하여 사용하면 된다)
- 표준화 : 평균을 기준으로 얼마나 떨어져 있느냐? 같은 기준으로 만드는 방법, 음수도 존재, 데이터의 최대최소값 모를때 사용. ( StandardScaler )
- 정규화 : 0 ~ 1 사이로 맞추는 것. 데이터의 위치 비교가 가능, 데이터의 최대 최소값 알떄 사용 ( MinMaxScaler )
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 방법1. 표준화
X_scaler = StandardScaler()
X_scaler.fit_transform( X )
array([[ 1. , -0.57735027, -0.57735027, 0.69985807, 0.58989097],
[-1. , -0.57735027, 1.73205081, -1.51364653, -1.50749915],
[-1. , 1.73205081, -0.57735027, -1.12302807, -0.98315162],
[-1. , -0.57735027, 1.73205081, -0.08137885, -0.37141284],
[ 1. , -0.57735027, -0.57735027, -0.47199731, -0.6335866 ],
[ 1. , -0.57735027, -0.57735027, 1.22068269, 1.20162976],
[-1. , 1.73205081, -0.57735027, 1.48109499, 1.55119478],
[ 1. , -0.57735027, -0.57735027, -0.211585 , 0.1529347 ]])
y # y는 0과 1로만 표현되므로 스케일링 과정을 거치지 않아도 된다
array([0, 1, 0, 0, 1, 1, 0, 1])
# 방법2. 정규화
X_scaler = MinMaxScaler()
X = X_scaler.fit_transform( X )
array([[1. , 0. , 0. , 0.73913043, 0.68571429],
[0. , 0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0.13043478, 0.17142857],
[0. , 0. , 1. , 0.47826087, 0.37142857],
[1. , 0. , 0. , 0.34782609, 0.28571429],
[1. , 0. , 0. , 0.91304348, 0.88571429],
[0. , 1. , 0. , 1. , 1. ],
[1. , 0. , 0. , 0.43478261, 0.54285714]])
y
array([0, 1, 0, 0, 1, 1, 0, 1])
Dataset을 Training 용과 Test용으로 나눈다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2, random_state=32)
# 80%는 학습용으로 하고, 20%는 테스트용으로 해라 (0.2 또는 0.25로 주로 사용한다)
# random_state 는 random seed값과 비슷한것이다
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, y_train)
검증하기 : MSE(mean squared error) 구하기
y_pred = regressor.predict(X_test)
# MSE
error = y_test - y_pred
(error ** 2).mean()
# 성능을 측정하기 위해서는 오차를 제곱해서, 부호를 먼저 없앤 후에 평균을 구한다
# RMSE (루트를 씌운 값이다)
np.sqrt((error ** 2).mean())
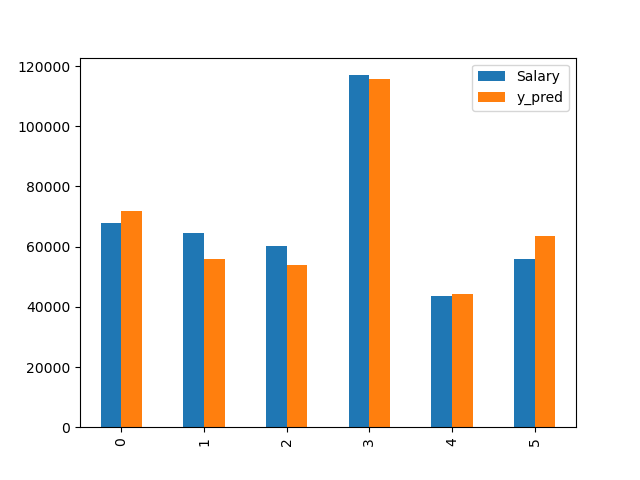
df_test = y_test.to_frame()
df_test.reset_index(drop=True, inplace=True)
df_test['y_pred'] = y_pred
df_test.plot(kind='bar')
plt.savefig('test.jpg')
plt.show()
'ML (MachineLearning)' 카테고리의 다른 글
| SVM(Support Vector Machine) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |
|---|---|
| KNN(K nearest neighbor) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |
| 데이터 불균형이 발생할 때, 데이터 리샘플링하기 (0) | 2024.04.15 |
| Logistic Regression (로지스틱 회귀) (0) | 2024.04.15 |
| Linear regression을 사용하여 신규 데이터 입력 시, 데이터 기반 예측 값 알려주기 (5) | 2024.04.15 |