Simple linear regression
하나의 변수로 X -> y를 알아낸다
Multiple linear regression
여러개의 변수로 X1, X2, X3 ... -> y를 알아낸다
여기서는 Multiple linear regression로 데이터 기반 예측값을 알아보도록 하겠다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
여러개의 데이터를 기반으로 Profit (수익)을 예측하려 한다.
df
| R&D Spend | Administration | Marketing Spend | State | Profit | |
| 0 | 165349.20 | 136897.80 | 471784.10 | New York | 192261.83 |
| 1 | 162597.70 | 151377.59 | 443898.53 | California | 191792.06 |
| 2 | 153441.51 | 101145.55 | 407934.54 | Florida | 191050.39 |
| 3 | 144372.41 | 118671.85 | 383199.62 | New York | 182901.99 |
| 4 | 142107.34 | 91391.77 | 366168.42 | Florida | 166187.94 |
| 5 | 131876.90 | 99814.71 | 362861.36 | New York | 156991.12 |
| 6 | 134615.46 | 147198.87 | 127716.82 | California | 156122.51 |
| 7 | 130298.13 | 145530.06 | 323876.68 | Florida | 155752.60 |
| 8 | 120542.52 | 148718.95 | 311613.29 | New York | 152211.77 |
| 9 | 123334.88 | 108679.17 | 304981.62 | California | 149759.96 |
| 10 | 101913.08 | 110594.11 | 229160.95 | Florida | 146121.95 |
| 11 | 100671.96 | 91790.61 | 249744.55 | California | 144259.40 |
| 12 | 93863.75 | 127320.38 | 249839.44 | Florida | 141585.52 |
| 13 | 91992.39 | 135495.07 | 252664.93 | California | 134307.35 |
| 14 | 119943.24 | 156547.42 | 256512.92 | Florida | 132602.65 |
| 15 | 114523.61 | 122616.84 | 261776.23 | New York | 129917.04 |
| 16 | 78013.11 | 121597.55 | 264346.06 | California | 126992.93 |
| 17 | 94657.16 | 145077.58 | 282574.31 | New York | 125370.37 |
| 18 | 91749.16 | 114175.79 | 294919.57 | Florida | 124266.90 |
| 19 | 86419.70 | 153514.11 | 0.00 | New York | 122776.86 |
| 20 | 76253.86 | 113867.30 | 298664.47 | California | 118474.03 |
| 21 | 78389.47 | 153773.43 | 299737.29 | New York | 111313.02 |
| 22 | 73994.56 | 122782.75 | 303319.26 | Florida | 110352.25 |
| 23 | 67532.53 | 105751.03 | 304768.73 | Florida | 108733.99 |
| 24 | 77044.01 | 99281.34 | 140574.81 | New York | 108552.04 |
| 25 | 64664.71 | 139553.16 | 137962.62 | California | 107404.34 |
| 26 | 75328.87 | 144135.98 | 134050.07 | Florida | 105733.54 |
| 27 | 72107.60 | 127864.55 | 353183.81 | New York | 105008.31 |
| 28 | 66051.52 | 182645.56 | 118148.20 | Florida | 103282.38 |
| 29 | 65605.48 | 153032.06 | 107138.38 | New York | 101004.64 |
| 30 | 61994.48 | 115641.28 | 91131.24 | Florida | 99937.59 |
| 31 | 61136.38 | 152701.92 | 88218.23 | New York | 97483.56 |
| 32 | 63408.86 | 129219.61 | 46085.25 | California | 97427.84 |
| 33 | 55493.95 | 103057.49 | 214634.81 | Florida | 96778.92 |
| 34 | 46426.07 | 157693.92 | 210797.67 | California | 96712.80 |
| 35 | 46014.02 | 85047.44 | 205517.64 | New York | 96479.51 |
| 36 | 28663.76 | 127056.21 | 201126.82 | Florida | 90708.19 |
| 37 | 44069.95 | 51283.14 | 197029.42 | California | 89949.14 |
| 38 | 20229.59 | 65947.93 | 185265.10 | New York | 81229.06 |
| 39 | 38558.51 | 82982.09 | 174999.30 | California | 81005.76 |
| 40 | 28754.33 | 118546.05 | 172795.67 | California | 78239.91 |
| 41 | 27892.92 | 84710.77 | 164470.71 | Florida | 77798.83 |
| 42 | 23640.93 | 96189.63 | 148001.11 | California | 71498.49 |
| 43 | 15505.73 | 127382.30 | 35534.17 | New York | 69758.98 |
| 44 | 22177.74 | 154806.14 | 28334.72 | California | 65200.33 |
| 45 | 1000.23 | 124153.04 | 1903.93 | New York | 64926.08 |
| 46 | 1315.46 | 115816.21 | 297114.46 | Florida | 49490.75 |
| 47 | 0.00 | 135426.92 | 0.00 | California | 42559.73 |
| 48 | 542.05 | 51743.15 | 0.00 | New York | 35673.41 |
| 49 | 0.00 | 116983.80 | 45173.06 | California | 14681.40 |
1. nan 처리
df.isna().sum()
R&D Spend 0
Administration 0
Marketing Spend 0
State 0
Profit 0
dtype: int64
2. X,y로 분리
y = df['Profit']
X = df.loc[ : , 'R&D Spend':'State' ]
3. 문자열 데이터는 숫자로
df['State'].unique()
array(['New York', 'California', 'Florida'], dtype=object)
# 원핫 인코딩
-원 핫 인코딩하면 원 핫 인코딩된 컬럼이 항상 맨 왼쪽에 위치하게 된다
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer( [ ('encoder', OneHotEncoder() , [3] ) ] , remainder= 'passthrough' )
X = ct.fit_transform(X)
X = ct.fit_transform(X)
# 피처 스케일링은 linear이므로 패스한다
(만약 피처스케일링을 해야한다면 이전 글을 참조하길 바란다)
4. traing과 test로 나누고 regression 모델을 만든다
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y , test_size=0.2, random_state=65)
#항상 이 형태여야 한다
test_size=0.2는 test 2 : traning 8 의 비율로 한다는 뜻이다. 실무에서는 주로 2 또는 2.5로 쓴다
random_state는 random의 seed값과 비슷한 개념이다
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, y_train)
5. regression 모델의 식 알아보기
Multiple linear regression에서는 여러개의 변수를 쓰는데, 이 예제에서는 변수가 아래와 같다.
| R&D Spend | Administration | Marketing Spend | State |
그런데, state는 원 핫 인코딩으로 문자열을 New York, California, Florida 세개로 나누었기 때문에,
아래와 같이 여섯개의 변수라고 할 수 있다.
R&D Spend
Administration
Marketing Spend
California (1, 0, 0)
Florida (0, 1, 0)
New York (0, 0, 1)
X가 총 6개의 변수이므로
y = aX1 + bX2 + cX3 + dX4 + eX5 + fX6 + g 와 같은 식을 사용한다고 할 수 있다.
여기서,
regressor.coef_array([ 8.29736108e+00, 1.35646415e+03, -1.36476151e+03, 8.24637324e-01,
-1.12195852e-02, 2.80920611e-02])
coef는 계수를 뜻하며 a, b, c, d, e, f에 해당한다.
regressor.intercept_46989.22920268966
intercept는 상수항을 뜻하며 g에 해당한다
즉,
y = 8.29736108e+00X1+ 1.35646415e+03X2 + -1.36476151e+03X3 + 8.24637324e-01X4 +
-1.12195852e-02X5 + 2.80920611e-02X6 + 46989.22920268966
이라는 식이 나온 것이다.
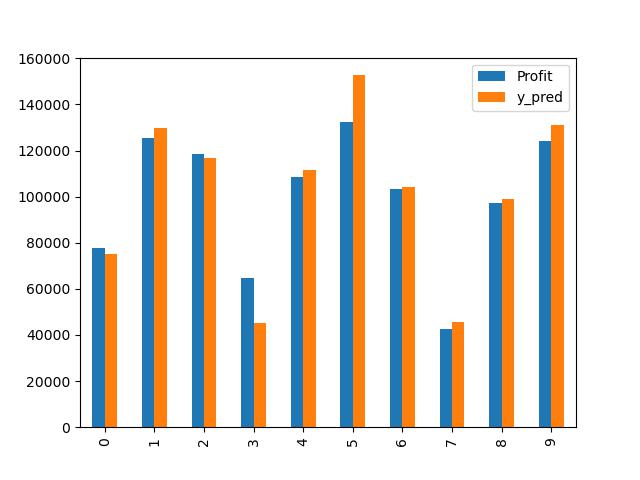
6. 데이터 입력받기 전, 임의로 테스트(test)해보고 오차 구해보기
y_pred = regressor.predict(X_test)
#MSE(오차 구하기)
((y_test - y_pred) **2).mean
df_test = y_test.to_frame()
df_test.reset_index(drop=True, inplace=True)
df_test['y_pred'] = y_pred
#도표로 확인하기
df_test.plot(kind='bar')
plt.savefig('test.jpg')
plt.show()
7. 데이터를 입력받는 실서버에 배포하기 위해서 regressor과 ct를 저장하기
import joblib
joblib.dump( regressor , 'regressor.pkl' )
joblib.dump(ct, 'ct.pkl' )
8. X를 입력받아서 y 예측하기
위의 re파일로 저장해서 실서버에 배포한 후에,
아래와 같은 새로운 데이터를 받았다. 이 데이터를 바탕으로 회사의 수익을 예측할 것이다
운영비는 15만달러, 마케팅비는 40만달러, 연구개발비 13만달러이고 회사위치는 Florida에 있다.
data = {'R&D Spend' : [130000,150000], 'Administration':[150000,110000],'Marketing Spend':[400000,600000], 'State':['Florida','New York']}
new_data = pd.DataFrame(data) #데이터프레임으로 꼭 만들어야 한다!
new_data
| R&D Spend | Administration | Marketing Spend | State | |
| 0 | 130000 | 150000 | 400000 | Florida |
| 1 | 150000 | 110000 | 600000 | New York |
new_data = ct.transform( new_data )
regressor.predict( new_data )
array([165102.43212675, 184941.14856592])
이를 통해서,
| R&D Spend | Administration | Marketing Spend | State | |
| 0 | 130000 | 150000 | 400000 | Florida |
의 수익(Profit)은 165102.43212675이고,
| R&D Spend | Administration | Marketing Spend | State | |
| 1 | 150000 | 110000 | 600000 | New York |
의 수익(Profit)은 184941.14856592 라는 것을 알 수 있다.
'ML (MachineLearning)' 카테고리의 다른 글
| SVM(Support Vector Machine) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |
|---|---|
| KNN(K nearest neighbor) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |
| 데이터 불균형이 발생할 때, 데이터 리샘플링하기 (0) | 2024.04.15 |
| Logistic Regression (로지스틱 회귀) (0) | 2024.04.15 |
| Regressor(회귀모델) 생성하고, MSE(평균제곱오차)구하는 방법 (0) | 2024.04.12 |