머신러닝의 비지도(unsupervised)학습
1. 평할/분할 기반의 군집 (Partition-based Clustering)
- 비슷한 특징을 갖는 데이터끼리 묶는것이다
- 주어진 데이터에 대해 미리 정의된 수의 군집을 형성하며, 데이터를 해당 군집에 할당하는 방식으로 동작한다
ex ) K-Means Clustering
2. 계층적 군집 (Hierarchical Clustering)
- 데이터를 순차적 또는 계층적으로 그룹화하는 알고리즘
- 데이터 포인트 간의 거리 또는 유사도를 기반으로 계층 구조를 형성하여 군집을 형성
- 계층적인 구조를 가지고 있어 군집화 결과를 다양한 수준에서 살펴볼 수 있으며, 시각적으로 표현하기 쉽다
- 사전에 군집의 개수를 지정할 필요가 없어 편리
- 큰 데이터셋에 대해서는 계산 비용이 증가할 수 있고, 특정 수준에서의 군집화 결과를 해석하는 것이 어려울 수 있다
ex ) 병합 군집화 (Agglomerative Clustering) , 분할 군집화 (Divisive Clustering)
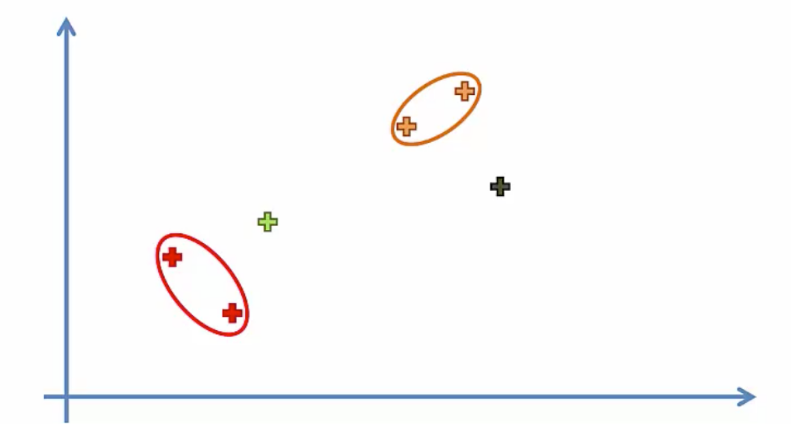
하이라키 클러스터링(Hierarchical Clustering) : 계층적 군집
- 점점 넓혀가면서 비슷한 개체를 군집으로 만들어나가는 형태이다
- 데이터 포인트 간의 거리나 유사성을 기반으로 계층적인 트리 구조를 형성
- 가장 짧은 거리를 가진 클러스터를 결합하여 더 큰 클러스터를 만든다

df
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | |
| 0 | 1 | Male | 19 | 15 | 39 |
| 1 | 2 | Male | 21 | 15 | 81 |
| 2 | 3 | Female | 20 | 16 | 6 |
| 3 | 4 | Female | 23 | 16 | 77 |
| 4 | 5 | Female | 31 | 17 | 40 |
| ... | ... | ... | ... | ... | ... |
| 195 | 196 | Female | 35 | 120 | 79 |
| 196 | 197 | Female | 45 | 126 | 28 |
| 197 | 198 | Male | 32 | 126 | 74 |
| 198 | 199 | Male | 32 | 137 | 18 |
| 199 | 200 | Male | 30 | 137 | 83 |
X = df.iloc[ : , 1 : ]
| Genre | Age | Annual Income (k$) | Spending Score (1-100) | |
| 0 | Male | 19 | 15 | 39 |
| 1 | Male | 21 | 15 | 81 |
| 2 | Female | 20 | 16 | 6 |
| 3 | Female | 23 | 16 | 77 |
| 4 | Female | 31 | 17 | 40 |
| ... | ... | ... | ... | ... |
| 195 | Female | 35 | 120 | 79 |
| 196 | Female | 45 | 126 | 28 |
| 197 | Male | 32 | 126 | 74 |
| 198 | Male | 32 | 137 | 18 |
| 199 | Male | 30 | 137 | 83 |
문자열 숫자로 바꾸기
X['Genre'].unique()
array(['Male', 'Female'], dtype=object)
'Male'과 'Female' 2개이므로 0과 1로만 바꾸면 되기때문에, 원핫인코딩(3개 이상)이 아닌 라벨 인코딩으로 하면 된다
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
X['Genre'] = encoder.fit_transform(X['Genre'])
X
| Genre | Age | Annual Income (k$) | Spending Score (1-100) | |
| 0 | 1 | 19 | 15 | 39 |
| 1 | 1 | 21 | 15 | 81 |
| 2 | 0 | 20 | 16 | 6 |
| 3 | 0 | 23 | 16 | 77 |
| 4 | 0 | 31 | 17 | 40 |
| ... | ... | ... | ... | ... |
| 195 | 0 | 35 | 120 | 79 |
| 196 | 0 | 45 | 126 | 28 |
| 197 | 1 | 32 | 126 | 74 |
| 198 | 1 | 32 | 137 | 18 |
| 199 | 1 | 30 | 137 | 83 |
sorted(X['Genre'].unique())
['Female', 'Male']
'Female'이 0, 'Male'이 1이라는 것을 알 수 있다.
하이라키 클러스터링은 피쳐스케일링 단계를 거치지 않는다
Dendrogram 그리기
유클리드 거리를 사용해서 와드 연결을 계산하고 덴그로그램을 사용하여 시각화 한다
덴그로그램 계층구조를 도식화한 그림을 덴그로그램이라 한다
import scipy.cluster.hierarchy as sch
sch.dendrogram( sch.linkage(X, method='ward') )#linkage : 연결을 어떻게 시킬것인가? 'ward' 메소드가 가장 일반적
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Distance')
plt.show()
ward 메소드는 계층적 군집화에서 사용되는 거리 측정 방법 중 하나이며 거리 측정 방법을 사용하여 계층적 군집화를 실행하는 Python 코드이다. 비교적 안정적이며 군집 간의 크기 차이에 민감하지 않아 널리 사용된다. 주어진 데이터셋에 대한 거리 행렬을 계산한 후에, 이를 사용하여 계층적 군집화를 수행할 수 있다.

from sklearn.cluster import AgglomerativeClustering
#AgglomerativeClustering는 병합적 군집화이다
hc = AgglomerativeClustering(n_clusters=5)
y_pred = hc.fit_predict(X)
df['Group'] = y_pred
df
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | Group | |
| 0 | 1 | Male | 19 | 15 | 39 | 4 |
| 1 | 2 | Male | 21 | 15 | 81 | 3 |
| 2 | 3 | Female | 20 | 16 | 6 | 4 |
| 3 | 4 | Female | 23 | 16 | 77 | 3 |
| 4 | 5 | Female | 31 | 17 | 40 | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 195 | 196 | Female | 35 | 120 | 79 | 2 |
| 196 | 197 | Female | 45 | 126 | 28 | 1 |
| 197 | 198 | Male | 32 | 126 | 74 | 2 |
| 198 | 199 | Male | 32 | 137 | 18 | 1 |
| 199 | 200 | Male | 30 | 137 | 83 | 2 |
df.loc[df['Group'] == 4, ]
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | Group | |
| 0 | 1 | Male | 19 | 15 | 39 | 4 |
| 2 | 3 | Female | 20 | 16 | 6 | 4 |
| 4 | 5 | Female | 31 | 17 | 40 | 4 |
| 6 | 7 | Female | 35 | 18 | 6 | 4 |
| 8 | 9 | Male | 64 | 19 | 3 | 4 |
| 10 | 11 | Male | 67 | 19 | 14 | 4 |
| 12 | 13 | Female | 58 | 20 | 15 | 4 |
| 14 | 15 | Male | 37 | 20 | 13 | 4 |
| 16 | 17 | Female | 35 | 21 | 35 | 4 |
| 18 | 19 | Male | 52 | 23 | 29 | 4 |
| 20 | 21 | Male | 35 | 24 | 35 | 4 |
| 22 | 23 | Female | 46 | 25 | 5 | 4 |
| 24 | 25 | Female | 54 | 28 | 14 | 4 |
| 26 | 27 | Female | 45 | 28 | 32 | 4 |
| 28 | 29 | Female | 40 | 29 | 31 | 4 |
| 30 | 31 | Male | 60 | 30 | 4 | 4 |
| 32 | 33 | Male | 53 | 33 | 4 | 4 |
| 34 | 35 | Female | 49 | 33 | 14 | 4 |
| 36 | 37 | Female | 42 | 34 | 17 | 4 |
| 38 | 39 | Female | 36 | 37 | 26 | 4 |
| 40 | 41 | Female | 65 | 38 | 35 | 4 |
| 42 | 43 | Male | 48 | 39 | 36 | 4 |
| 44 | 45 | Female | 49 | 39 | 28 | 4 |
'ML (MachineLearning)' 카테고리의 다른 글
| 딥러닝 : Neural Networks 으로 Classification(분류) 하기 (2) | 2024.04.16 |
|---|---|
| 머신러닝 알고리즘 개념 요약 (0) | 2024.04.16 |
| K-Means 알고리즘 (0) | 2024.04.16 |
| DTree(Decision Tree) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |
| SVM(Support Vector Machine) 알고리즘으로 새로운 데이터 카테고리 분류하기 (0) | 2024.04.15 |